Low effort exam grading
Last semester Anton was lecturing on the undergraduate Solid State Physics course at TU Delft. The course lasted several weeks, and each week there was a mini exam that students on the course could take for partial credit. This was a big course with 200 participants, and the prospect of having to manually grade 200 exam manuscripts every week was not something that anyone on the course team was looking forward to.
Anton came up with the idea to try and streamline the grading process by grading the manuscripts electronically, rather than by hand. The idea would be to have some kind of web app where we could upload scans of the exam manuscripts, and then view and assign feedback for the students' answers on a question-by-question basis. Although there is a local startup, Ans, that provides basically this service, the cost is quite prohibitive. We decided that, for our needs, a "just good enough" solution would be satisfactory.
The result of a few week's worth of evening hacking sessions is Zesje, named for the Dutch term zesjescultuur, which is the attitude of applying the minimal amount of effort to get a passable result. While a bit tongue in cheek, we think that the name represents well the aims of the project. In fact, the success of the project has been entirely out of proportion to the effort put into it; the software was used by the statistical physics course team last semester, and several other courses in the department will trial it in the coming academic year.
Below you can see the main interface that you would interact with while grading an exam: we are logged in as Anton, and are grading problem 3a of an exam called "TN2844-retake-2017". At the bottom is the scanned reponse of a single student (name removed for anonymity), and just above is a list of possible feedback options that may be selected for this problem. Just above that is the interface for selecting different students' submissions for the same problem, and above that is where we can select different tabs e.g. to edit the possible feedback options for this question.
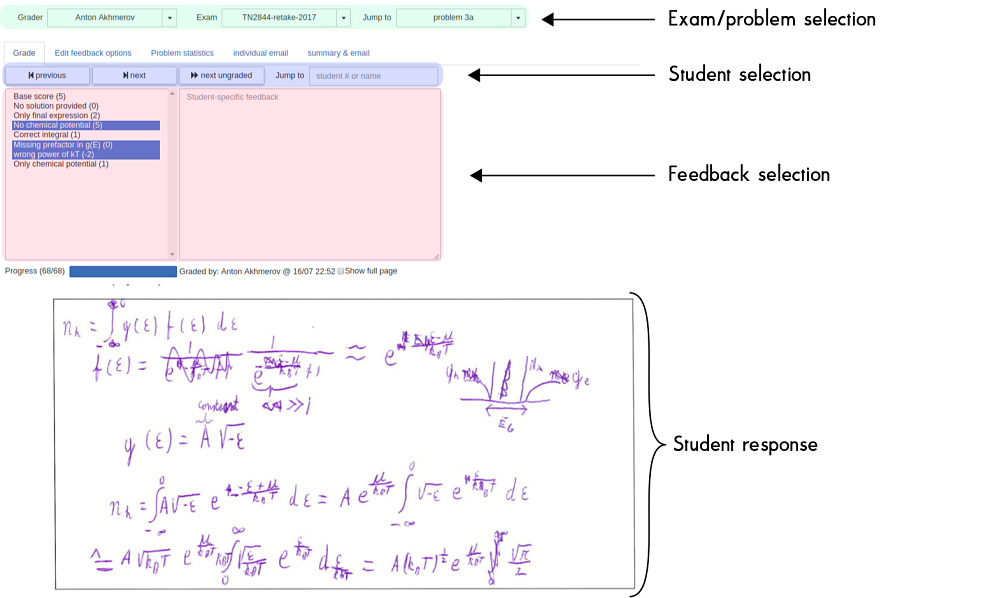
A screenshot of the main Zesje interface.
In the rest of this post I'll give a bit of insight into the different technologies that we used to build Zesje, as well as our motivation for each piece (spoiler alert: the motivation was to write as little code as possible).
We have the technology!
Our first task was to generate PDFs for the exam the students would be taking. Anton was already writing the exam in Latex anyway, so the natural solution was to write a package that can do things like define labeled answer boxes (e.g. "question 1a"), and insert machine-readable identifiers into each page (so that the exam pages do not need to be scanned in order). Luckily there is already an excellent Latex package for generating QR codes, so that part was pretty easy; we uniquely identify an exam page by the name of the exam, a submission number, and the page number within the submission. In addition to inserting elements into the generated PDF, the Latex class we wrote also generates a metadata file that encodes the positions and extents of the answer boxes within a page. This information is later used to extract the answer to a specific question from the scanned pages.
After the students had completed the exam we could scan it in; we had access to some
pretty nifty scanners that could scan an entire stack (400 or so pages) in a matter
of a few minutes. Our next task was to read the scans and group pages together by
their submission ID (corresponding to a single student's answers). This amounted to
getting the coordinates of the QR codes from our previously-generated metadata file
and using zbar (although any other QR code library
would have worked too) to identify the page. We also toyed a bit with using
OpenCV to identify students' ID numbers (we had students
fill in their IDs by shading appropriate entries in a grid), but this was pretty
hit-and-miss and depended a lot on the scan quality. It is, of course, entirely
possible that we just hadn't tuned the image recognition parameters correctly,
but in the spirit of Zesje we decided not to optimize this O(# of students)
cost per exam, reasoning that it is the same for the human grader as just grading
one extra question.
OK, so now we had a bunch of scans grouped together according to which student submitted them; now all we had to do was grade them! Obviously we would need some sort of database into which to record the feedback and grades the students received for each problem. We knew we wanted to use an object-relational mapper (ORM) — because only people with too much time on their hands write raw SQL anymore — and decided on pony over other more established candidates (e.g. SQLAlchemy) because it looked so damn simple to use! The price for this simplicity, as we later learned, is that Pony seems to do some pretty gnarly things under the hood, like inspecting raw Python bytecode of generator expressions that you pass it. Most of the time this is pretty well hidden, but would sometimes surface like a great leviathan rising from the deep in a cacophony of wailing and garbled error messages. On the plus side we got plenty of laugh-out-loud moments when googling for how to get stuff done:
A typical scene when trying to migrate a database to a new schema using Pony ORM.
So yeah, ponies. Anyway. Our data model consisted of having a bunch of possible feedback
for each question, such as "all correct" or "missing factor of 2", which are editable
during grading — students' responses are unpredictable! — and which could be assigned to
student responses. This also neatly compartmentalized the problem of designing
a grading scheme, as the points awarded for each feedback option could be modified
a posteriori for O(1) effort, after having consulted with the whole course team.
We also gain extra transparency, because a student's final grade is just a function
of the feedback options that were assigned to them, which is great!
Next was an important piece of the puzzle — the user interface. Because it made sense for all the PDF scanning etc. to happen once, and for several graders to be able to grade simultaneously, a web app seemed the most sensible choice. Just one problem — web apps are a lot of effort! Even the most basic web app requires maintaining an entire extra software stack (for the frontend), in addition to trying to get the frontend and backend to act as a single coherent piece [1] ; ain't nobody got time for that. The solution came in the form of ipywidgets; a library of Python objects that interact with other Python code, but which know how to represent themselves as HTML. The idea is that you can have, say, a text box displayed in a web page whose contents can be read and written to "directly" by Python code executing on the server. IPywidgets handles all the nasty details (and Javascript) related to transferring these state changes between the browser and the server. We had actually been using a subset of these widgets for some time within the group (mainly for interactive simulations and data visualization), and so already knew how to work with them. Our web app then consisted of a bunch of Jupyter notebooks that declare the layout of the rendered page (again, by composing Python objects) and the behavior (by binding Python functions to certain events, such as the user clicking a button) and the rest was handled by Jupyter. Jupyter notebooks are also incorporating components to make it easy to create such workflows as "dashboards", which hide the code from the person viewing the notebook and allow them to only interact with the HTML widgets presented by the code. We used the (unfortunately now deprecated) dashboard server that runs a bunch of notebooks and serves the resulting dashboards as interactive web pages; it even includes password authentication, which meant that we could secure access to Zesje instances for no extra effort — score!
The final piece of functionality was something that we kind of just threw in because it didn't cost us much, but turned out to be a major boon for the students: personalized feedback. After grading, each student has a set of feedback options assigned to them from the rubric for each problem. These feedback options have a number of points associated with them, and also a detailed explanation of what the feedback means. The grader only needs to define this feedback option once, but can then assign it to a number of students. It's then pretty easy to write an email template (we used the Jinja2 templating language because we were familiar with the syntax) that enumerates the feedback the student received for each answer (with the detailed explanations). This template can can be rendered for each student and mailed to them directly with a PDF attachment of their scanned exam. This feature turned out to be immensely popular, as the feedback we were able to give was of much higher quality (graders are more motivated to give detailed feedback if they can reuse this feedback on several students) and delivered in a more convenient and timely manner.
So that's our stack! What was quite remarkable was how little "boilerplate" we actually needed to get all this functioning; it just goes to show that you can actually get some pretty cool results just by gluing together existing code.
Final thoughts
Zesje is, of course, prototype-level software that was hacked together in a few evenings and weekends to achieve a very specific goal. The consequences of this are code that is hacky at times, coupled with a user interface only a mother could love. The next iteration of Zesje will concentrate on refactoring to make the app more extensible in the future, and rethinking our choice of technologies, notably in the user interface. Despite this, the initial prototype was certainly not a waste of time; it allowed us to clearly demonstrate that grading scanned exams is both easier, more transparent and more insightful than grading paper. This not only delivers value to the course team (they get to spend less time grading), but also to the students (they get personalized feedback at no extra cost to the course team).
Those interested in learning a bit more can check out a sandbox deployment of Zesje over here.